Web Scraping (also called Web Data extraction, Screen Scraping, Web Harvesting) is a computing technique used to extract huge amounts of data from the web. The extracted data is usually saved to a file in the local storage or in a database table. The data available on most websites are meant to be consumed by using a web browser. The underlying data behind the sites is not structured and hence cannot be extracted easily. Most websites on the internet don’t provide any option to save the data to your computer directly. The only option you have is to copy and paste the displayed data manually, which is a hectic and inefficient task. This approach might be viable if you require only a tiny amount of data, but is never an option when you need data for business use cases.
Web scraping techniques fill this gap by automating the whole process – a computer program will visit the websites and extract the required data for you, all within a fraction of the time. A Web Scraping setup will interact with the websites by mimicking a human visitor using it with a browser. But rather than displaying the page served by the site on a screen, the web scraping tool will save the required data points from the site to a database or local file.
The main functions of a web scraping setup are:
- Recognizing HTML site structures
- Extracting and transforming the content
- Storing the scraped data
- Extracting data from APIs
GOOD BOTS AND BAD BOTS
- Good bots are the ones that obey the rules and guidelines set by the websites they crawl. They often identify themselves in their HTTP header as belonging to the organization they work for. Bad bots usually create false HTTP user agents to hide themselves from the webmasters.
- Legitimate bots abide the website’s robots.txt file and only crawls the pages that are allowed for crawling. They also follow the best practices of web scraping to avoid causing any sort of issues to the website. Bad bots don’t follow any guidelines and could even cause issues to the site by making frequent requests.
High end resources are required to run a web scraping setup and most DaaS providers invest heavily in servers and other resources needed to handle vast amounts of data.
HOW WEB SCRAPING WORKS
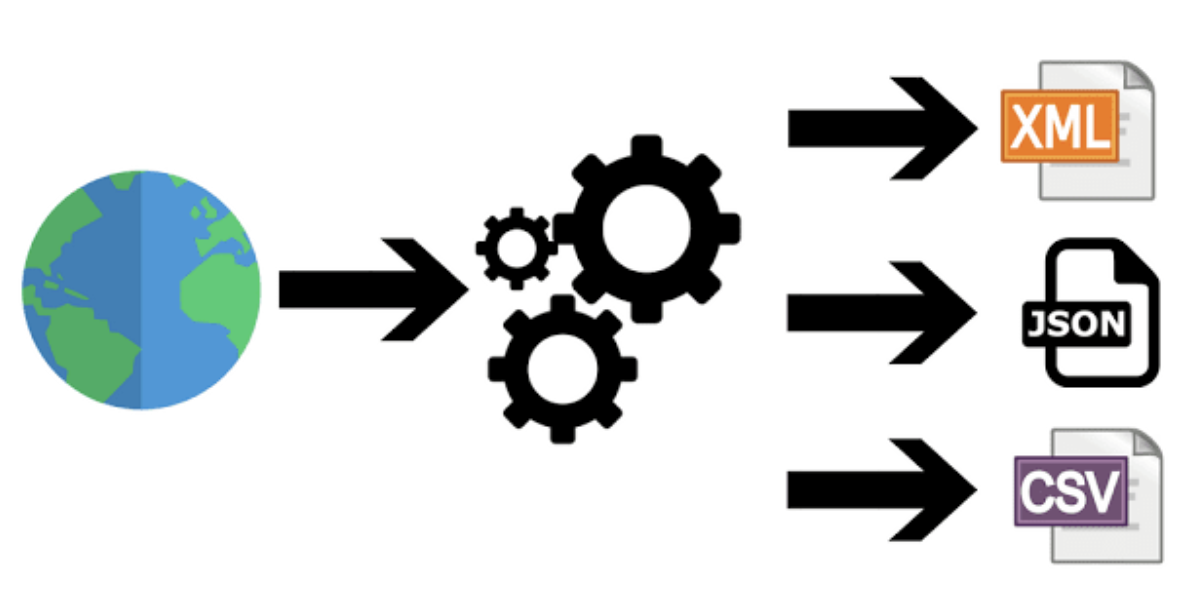
Web scraping is not a straightforward process due to the dynamic nature of websites on the internet. Every site would have a different structure and layout, which makes it impossible to build a one size fits all web scraper. The web web scraping process involves 3 main steps.
Step 1: Defining the Sources and Data Points
This is the first step in the web scraping process. Before the crawler can be setup, the sources to be crawled must be defined and checked for feasibility. This step is crucial as the quality of the data will depend on the quality of the sources you select. Once the sources are defined, the data points required from them must be identified. Data points are pieces of information available on the pages to be scraped.
Step 2. Setting Up the Crawler
Setting up the crawler is the most complicated task in web scraping. It demands high end programming skills and a reasonable amount of time that would go into figuring out what html tags hold the required data points. Once the html tags are identified, the crawler is programmed to traverse through the sources sites and extract the data. The crawler is then deployed on servers specially tuned for handling vast amounts of data. The crawler will now start extracting the data and saving it to a dump file.
Step 3. Cleansing And Structuring
This is the final step of the web scraping process and makes the data ready for consumption. The initial dump file created by the web crawler will be typically unstructured and contain noise. Noise is the unwanted html tags and pieces of text that gets scraped along with the data. The data is passed through a cleansing setup to remove the noise. Finally, the data is given a proper structure to ensure compatibility with databases and analytics systems.
DIFFERENT APPROACHES TO WEB SCRAPING
Different approaches and techniques are used for web scraping. Some are more suitable for large scale data extraction for business requirements while some others are only suitable for small, one time extraction needs. Following are the common methods and technologies used for web scraping:
DIY Web Scraping Tools
Standalone tools are available for web scraping. These tools don’t require the user to possess any technical skills at all. Web scraping with such DIY tools is usually a straightforward process as most of them have a visual interface. However, DIY tools are not an ideal solution if your web scraping requirements is of large scale. This is because of the less customization options available on the DIY web scraping tools. Most of the standalone web scraping tools cannot handle dynamic websites or large scale extraction.
Web Scraping Services (DaaS)
There are web scraping services that provide ‘data as a service’, which means you can forget all the complicated procedures involved in web scraping and get the required data, the way you want it. You will only have to be involved in the initial stages like providing your requirements to the vendor. A scraping service provide will take your requirements, like URLs to be scraped, data points to be extracted and the frequency at which you want the crawls to run. The data provider will setup the web crawler and handle all other tasks associated with it, leaving you with clean, structured data to work on.
APPLICATIONS OF WEB SCRAPING
Price Intelligence
 With the tightening competition in the Ecommerce space, having the right pricing has become a crucial factor for staying in the business. Price intelligence is all about having real time pricing data from your competitors. With a web scraping setup, you can have an edge in the competition by updating your prices with reference to your competitors’. This is extremely useful in industries where the purchase decisions of customers are hugely impacted by the price of the products.
With the tightening competition in the Ecommerce space, having the right pricing has become a crucial factor for staying in the business. Price intelligence is all about having real time pricing data from your competitors. With a web scraping setup, you can have an edge in the competition by updating your prices with reference to your competitors’. This is extremely useful in industries where the purchase decisions of customers are hugely impacted by the price of the products.
Sentiment Analysis
 Sentiment analysis is used by major brands to monitor customer sentiments and reactions on their brand and products. This is extremely crucial as social networks and conversations happening there can have a significant impact on brand reputation these days. Sentiment analysis is done by setting up web crawlers to monitor social media sites for keywords associated with your brand. Finding and fixing issues becomes easier with brand monitoring and sentiment analysis using web scraping.
Sentiment analysis is used by major brands to monitor customer sentiments and reactions on their brand and products. This is extremely crucial as social networks and conversations happening there can have a significant impact on brand reputation these days. Sentiment analysis is done by setting up web crawlers to monitor social media sites for keywords associated with your brand. Finding and fixing issues becomes easier with brand monitoring and sentiment analysis using web scraping.
Market Research
 Since the web has evolved into a huge data warehouse, market research benefits a lot from web data. Web scraping can be used to conduct an extensive market research to find new opportunities or evaluate the existing ones. As huge amounts of data is a must for the effectiveness of the research, web scraping is the only viable solution here.
Since the web has evolved into a huge data warehouse, market research benefits a lot from web data. Web scraping can be used to conduct an extensive market research to find new opportunities or evaluate the existing ones. As huge amounts of data is a must for the effectiveness of the research, web scraping is the only viable solution here.
Content Aggregation
 Content aggregation is growing in demand as many websites need huge data sets of job listings, real estate listings, classifieds ads and the like to build web portals for the same. As the amount of data required for this use case can be significantly large, automated web scraping technologies are the best option to aggregate this data. There are also scraping solutions specifically meant for extracting data from WordPress blogs.
Content aggregation is growing in demand as many websites need huge data sets of job listings, real estate listings, classifieds ads and the like to build web portals for the same. As the amount of data required for this use case can be significantly large, automated web scraping technologies are the best option to aggregate this data. There are also scraping solutions specifically meant for extracting data from WordPress blogs.
Conclusion
Big data has nearly attained the status of an asset among businesses that are strategically extracting, analyzing and driving business decisions using it. When used in the right way, web scraping and data extraction techniques can help augment your business intelligence activities and help take the growth graph higher.